
目次(まとめ)
◾️ Rのplotlyパッケージを使って散布図を色分けする
◾️ 次元圧縮の結果を特徴量の大きさによって色分けする
こんにちは、みっちゃんです。
今回の記事では、無料の統計解析ソフトウェアであるRをつかって散布図を描く際に、それぞれの点に連続的に変化するような色を割り当てて、ヒートマップのように表示する方法を紹介します(Rについてはこちらの記事をご参照ください)。
Rのplotlyパッケージを使って散布図を色分けする
ここでは、以下のように、正規分布にしたがう乱数を10個ずつ変数 "x" と "y" に保存して散布図にすることを考えます。
> x <- rnorm(10)
> y <- rnorm(10)散布図をヒートマップのように色分けするために、"plotly" パッケージをインストールして使える状態にします。
> install.packages("plotly")
> library(plotly)この "plotly" パッケージでは、データフレーム型のデータを取り扱うので、以下のように、データフレーム型の変数 "data" を準備します。
> data <- data.frame(x, y)
> data
x y
1 -0.99062837 -1.0032767
2 -0.74323922 1.7578982
3 0.05470839 -0.3100840
4 1.40402747 0.2827941
5 0.77926949 0.1458672
6 0.22671545 0.7865892
7 0.04208401 1.7374705
8 1.73918747 0.6613166
9 -0.10033588 0.5183486
10 2.12288393 -1.8416065"data" 変数は、"x" の列と "y" の列に、それぞれ10個ずつの乱数が入っているようなデータフレームになっています。
以下のように実行すれば、その変数が何型なのか確認することができます。
> class(x)
[1] "numeric"
> class(y)
[1] "numeric"
> class(data)
[1] "data.frame""plotly" パッケージを使って散布図を描くためには以下のように "plot_ly" 関数を実行します。
> plot_ly(data, x = data$x, y = data$y, color = data$x, colors = c("green", "white", "red"))この実行結果は、以下のようにブラウザ上に表示され、"color" で指定した "data" の "x" 列の値に沿って色分けされています。
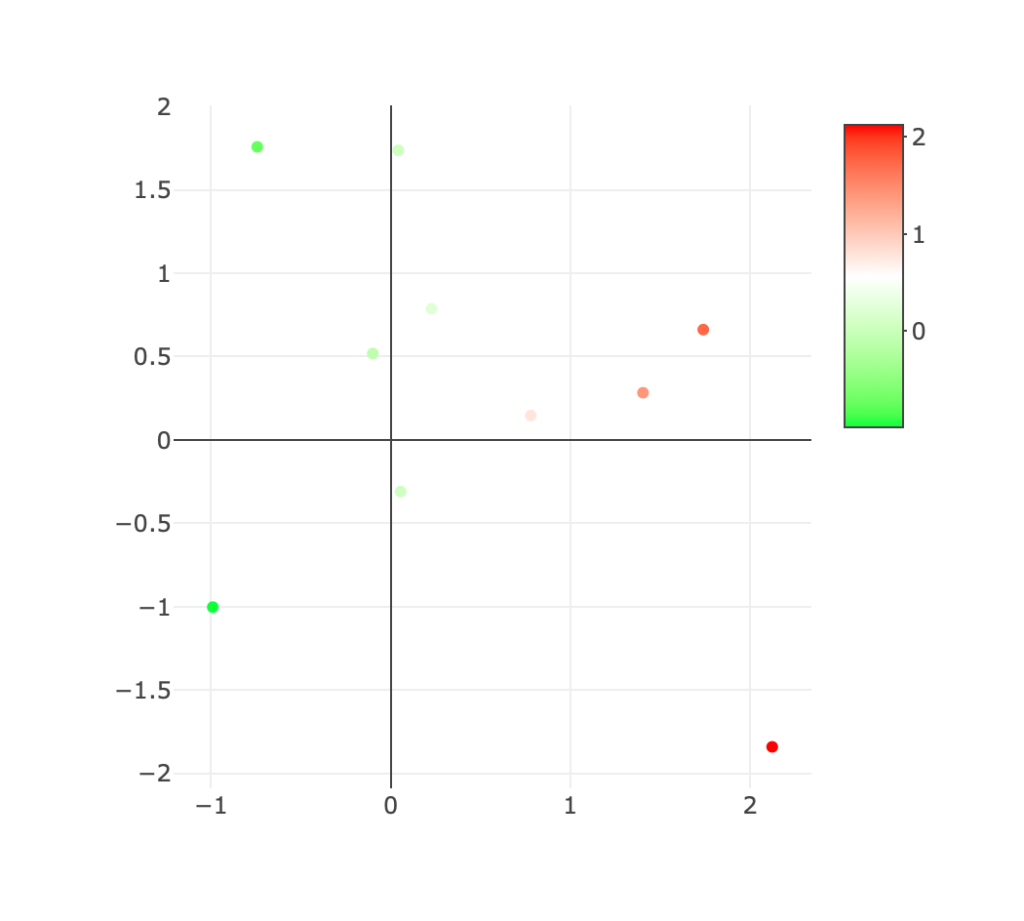
ここでは、"x" の値の大小関係に基づき、緑色から赤色が割り当てられているので、横軸に沿って、緑から赤へと、点の色が変わっていることがわかります。
"colors" の指定は、例えば、"rainbow(12)" などに指定することも可能です(12という数字は色分けの細かさで、値を大きくするほど細かい色分けになります)。
また、以下のように実行しても、同じ結果を得ることができます。
> plot_ly(data, x = ~x, y = ~y, color = ~x, colors = c("green", "white", "red"))次元圧縮の結果を特徴量の大きさによって色分けする
上の例では、2次元データの散布図を例にしましたが、多次元データに対する次元圧縮の結果を、任意の次元の値に応じて色分けすることも可能です。
ここでは、以前の記事と同様に、"mtcars" のデータを使って主成分分析(PCA)を実行して得られた次元圧縮の結果を使用します。
> data <- scale(mtcars)
> data.pca <- prcomp(data)"mtcars" というデータセットは、さまざまな車について、以下のような11個の特徴量を集めたデータです。
> colnames(data)
[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
[11] "carb"ここでは、主成分分析(PCA)を行って得られた第1主成分、第2主成分をプロットして、それぞれの点を "mpg" の値で色分けしてみます。
まず、以下のようにデータフレーム "frame" を準備します。
> frame <- data.frame(data.pca$x[,1], data.pca$x[,2], as.data.frame(data)$mpg)
> names(frame) <- c("PC1", "PC2", "mpg")このように実行すると、"frame" は以下のような中身になっています。
> head(frame)
PC1 PC2 mpg
Mazda RX4 -0.64686274 1.7081142 0.1508848
Mazda RX4 Wag -0.61948315 1.5256219 0.1508848
Datsun 710 -2.73562427 -0.1441501 0.4495434
Hornet 4 Drive -0.30686063 -2.3258038 0.2172534
Hornet Sportabout 1.94339268 -0.7425211 -0.2307345
Valiant -0.05525342 -2.7421229 -0.3302874それぞれの車の名前に対して、第1主成分(PC1)、第2主成分(PC2)、mpg値が並んでいます。
このデータを使って、PC1とPC2の散布図を作成し、mpg値にしたがって色分けしてみます。
> plot_ly(frame, x = ~PC1, y = ~PC2, color = ~mpg, colors = c("green", "white", "red"))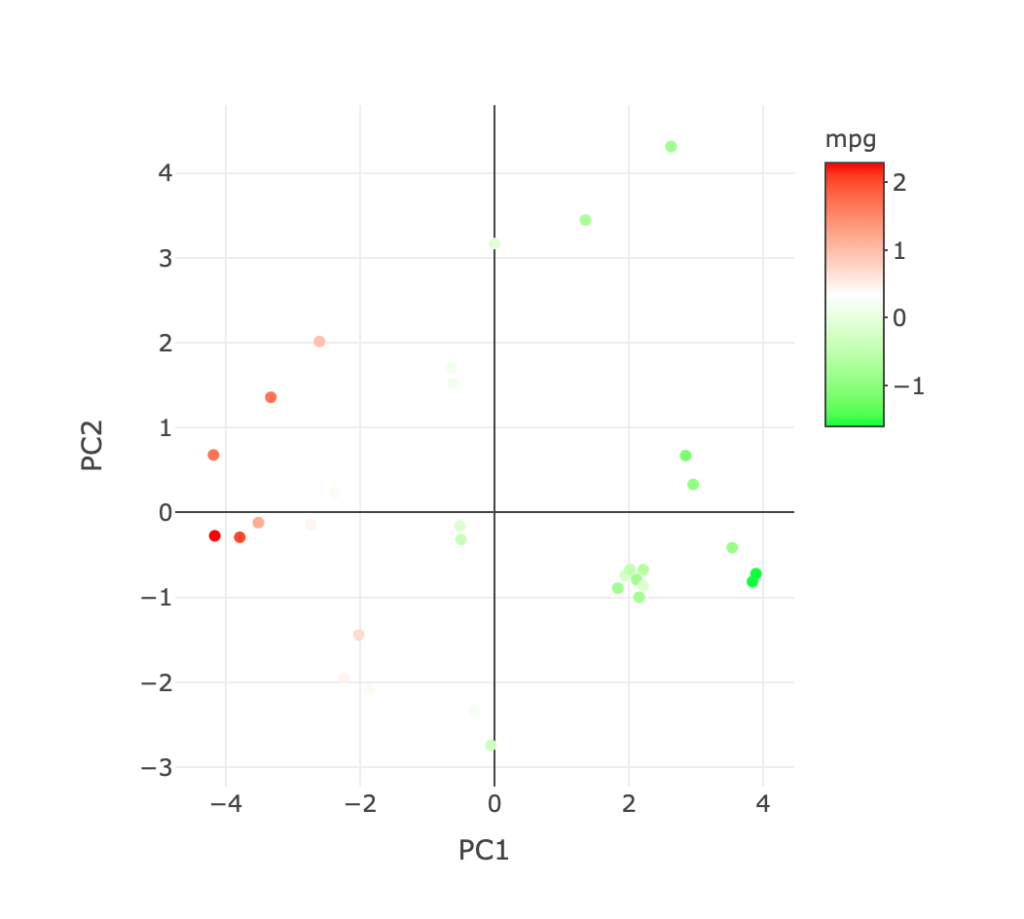
この結果から、"mpg" 値が大きい車は第1主成分が小さい領域に分布し、"mpg" 値が小さい車は第1主成分が大きい領域に分布していることがわかります。
