
目次(まとめ)
◾️ データとデータがどれぐらい似ているかを計算
◾️ クラスター分析を行なった結果を樹形図として可視化
◾️ オプションをつけて、ラベルを揃えることができる
◾️ 樹形図のラベルの情報だけを取得することも可能
こんにちは、みっちゃんです。
今回の記事では「多くの特徴をもつデータが複数あった時に、それらがどれぐらい似ているのか可視化したい」という方向けに、Rを使った樹形図の作り方を解説します。
データとデータがどれぐらい似ているかを計算
まず、RをMacOSのターミナル上で開きます(以前の記事をご参照ください)。
$ R -q今回の記事では、車の性能データである”mtcars”を用いて解説していきます。
まず、"mtcars"という変数の型を確認するために、以下のように入力します。
> typeof(mtcars)この結果をみると、"mtcars"という変数が「リスト型」の変数になっているので、樹形図作成に使えるように「ダブル型」の変数に変換します。
> data <- as.matrix(mtcars)樹形図を作成するためには、まずはデータとデータの距離を測るため、以下のように実行します。
> distant <- dist(data)変数 "distant" の中身を確認すると、以下のように、車と車の距離が保存されています(一部抜粋)。
> distant
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
Mazda RX4 Wag 0.6153251
Datsun 710 54.9086059 54.8915169
Hornet 4 Drive 98.1125212 98.0958939 150.9935191
Hornet Sportabout 210.3374396 210.3358546 265.0831615 121.0297564
:このデータを見ると、例えば、"Mazda RX4 Wag" という車と "Mazda RX4" という車との距離が近い(= 0.6153251)、つまり、よく似た車であることがわかります。
クラスター分析を行なった結果を樹形図として可視化
距離データ "distant" をもとに、以下のように、クラスター分析を行います(クラスター解析については、以前の記事をご覧ください)。
> cluster <- hclust(distant, method="average")ここでは、クラスター分析の手法として "average" を指定しています。
手法としては、"ward.D", "single", "complete", "average", "mcquitty", "median", "centroid", "ward.D2" を指定することができます。
これらは、クラスターとクラスターがどれぐらい似ているかを評価するための手法なので、どの手法を選ぶかによって、得られる樹形図も変わってきます(詳細は、以前の記事をご覧ください)。
樹形図を作図するためには、以下のように実行します。
> plot(cluster)樹形図は以下のように作成されます。
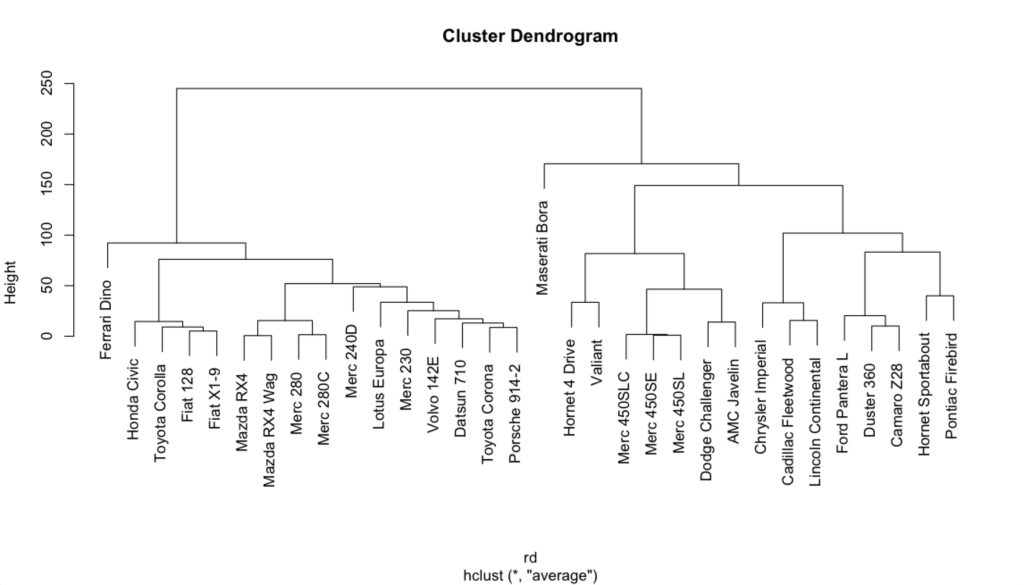
オプションをつけて、ラベルを揃えることができる
上に示した樹形図では、車の名前(ラベル)の表示箇所がバラバラで、統一感がないと感じる方もいるかもしれません。
それを改善するためには、plot関数の中で "hang = -1" と指定して、以下のように実行すればOKです。
> plot(cluster, hang = -1)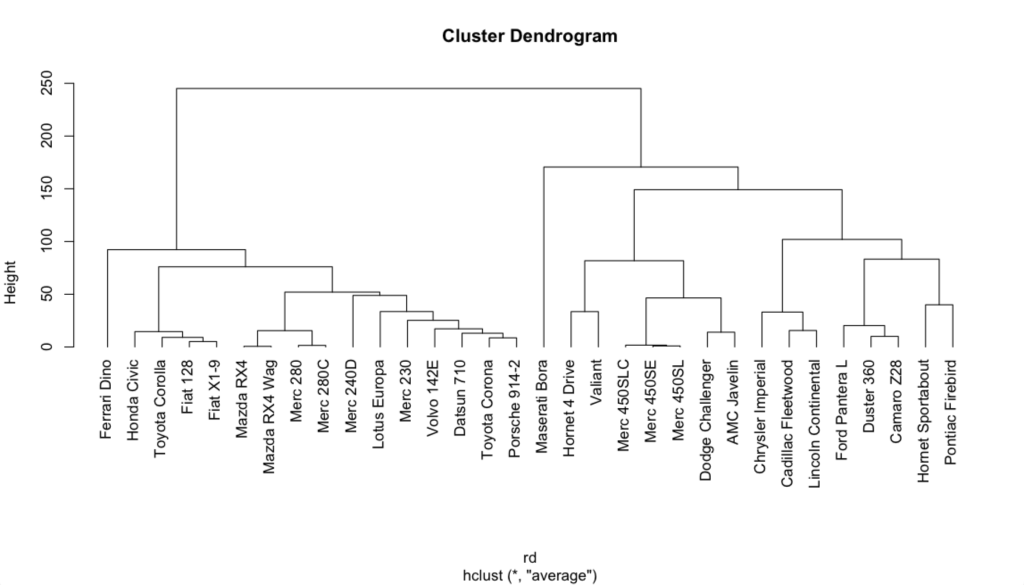
樹形図のラベルの情報だけを取得することも可能
今回示した樹形図では、車の名前(ラベル)をすべて表示することができていますが、データが大きくなるほど、ラベルを区別することが難しくなります。
そこで、以下のように実行することで、ラベルの名前を手にいれることができます。
> cluster$labels[cluster$order]とても便利なので、困った時には、ぜひ活用してみてください。
