
目次(まとめ)
◾️ Rを使えば、ヒートマップによるデータの可視化ができる
◾️ データに応じて、色分けを制御するオプションを変更する必要がある
◾️ ヒートマップのラベルの情報だけを取得することも可能
◾️ 関連記事
こんにちは、みっちゃんです。
今日は、データを可視化する「ヒートマップ」を解説したいと思います。
データ解析を日頃やっている方には、ヒートマップはお馴染みだとは思いますが、手軽に使える反面、気を付けるべきポイントがあります。
Rを使えば、ヒートマップによるデータの可視化ができる
ヒートマップとは、データの値の大きさによって、色を変えて、地図のように示した図です。
まず、RをMacOSのターミナル上で開きます(以前の記事をご参照ください)。
$ R -qヒートマップの描き方はいくつかありますが、私は「gplots」というパッケージの利用をお勧めします。なぜなら、色の違いに対応する情報(カラーバー)が提供されるからです。
> install.packages("gplots")
> library(gplots)今回の記事では、車の性能データである”mtcars”を用いて解説していきます。
まず、"mtcars"という変数の型を確認するために、以下のように入力します。
> typeof(mtcars)この結果をみると、"mtcars"という変数が「リスト型」の変数になっているので、ヒートマップ作成に使えるように「ダブル型」の変数に変換します。
> data <- as.matrix(mtcars)ヒートマップを作成するためには、以下のように入力するだけです。
> hv <- heatmap.2(data)ヒートマップは以下のように作成されます。
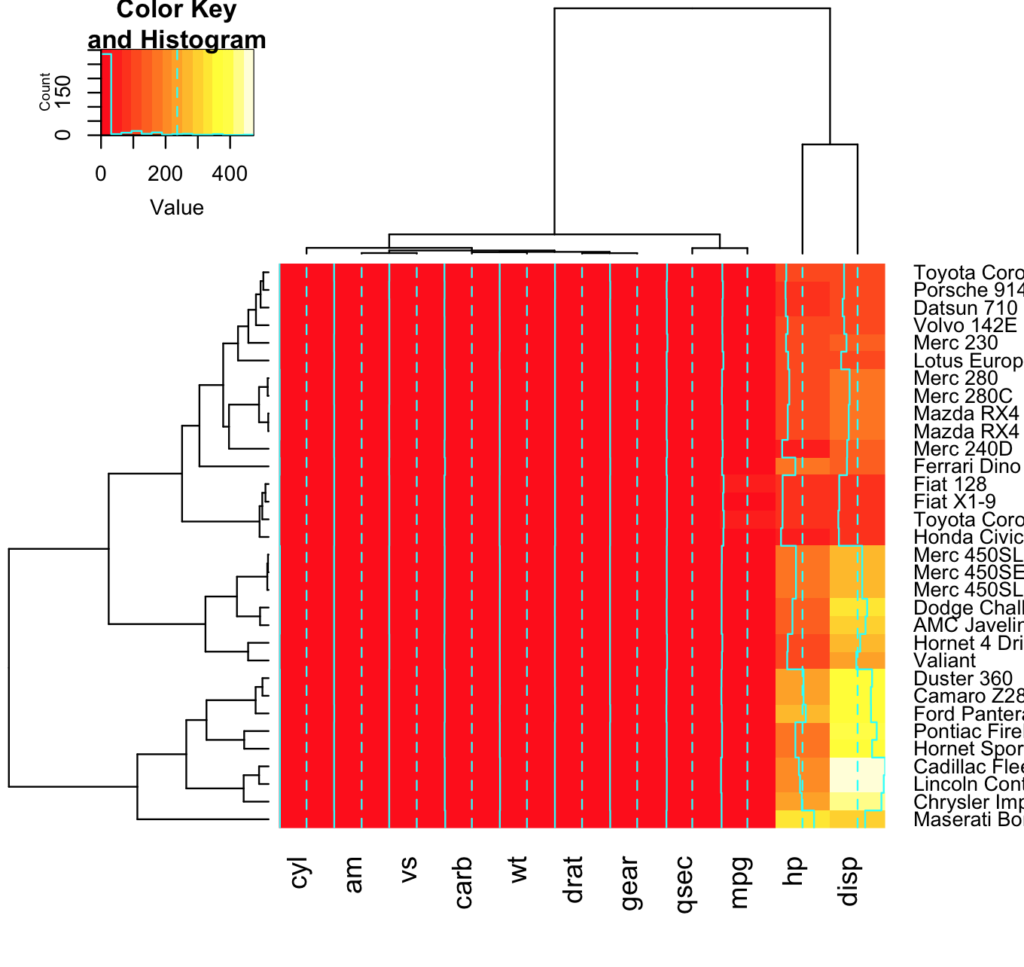
ヒートマップには、行の名前(車の名前)と列の名前(車の性能に関する指標)が並べられており、それぞれの車と性能に対応する場所に色が塗られています。
例えば、下から3番目の"Lincoln Con..."という車では、"disp"という指標の色が"白色"になっています。上に示しているカラーバーを見ると、白色は"460"ぐらいの数字であるということに見ることができます。実際に、下に示している表において同じデータを確認すると、"460"になっています。
また、ヒートマップの上と左にある枝分かれしているものは「樹形図」というもので、以前の記事で紹介した「クラスター分析」で得られるものです。上の樹形図は、車の性能がどれぐらい似ているかを示し、左の樹形図は、車と車がどれぐらい似ているかを示しています(ちなみに、デフォルトの設定でヒートマップを作成すると、「最長距離法」に基づいてクラスターが形成されます)。
ちなみに、クラスター分析のオプションを変えたければ、以下のように実行します。*****の部分に、"single"(最短距離法)、"complete"(最長距離法)、"average"(群平均法)、"centroid"(重心法)、"median"(メディアン法)、"mcquitty"(McQuitty 法)、"ward.D"(Ward 法)を指定します。
> hv <- heatmap.2(data, hclustfun = function(x) { hclust(x, method = "*****") })また、青い線で示している情報は、以下のようなオプションを追加することで、非表示にすることができます。
> hv <- heatmap.2(data, density.info = "none", trace = "none")データに応じて、色分けを制御するオプションを変更する必要がある
しかし、図1をみると、ある問題に気づきます。
それは、「色がほとんど赤になってしまっている」ということです。
そもそも、車の性能を表す指標によって、単位が違うのだから、同じカラーバーで示すのは問題です。
ここで、"mtcars"というデータについて、もう一度確認します。
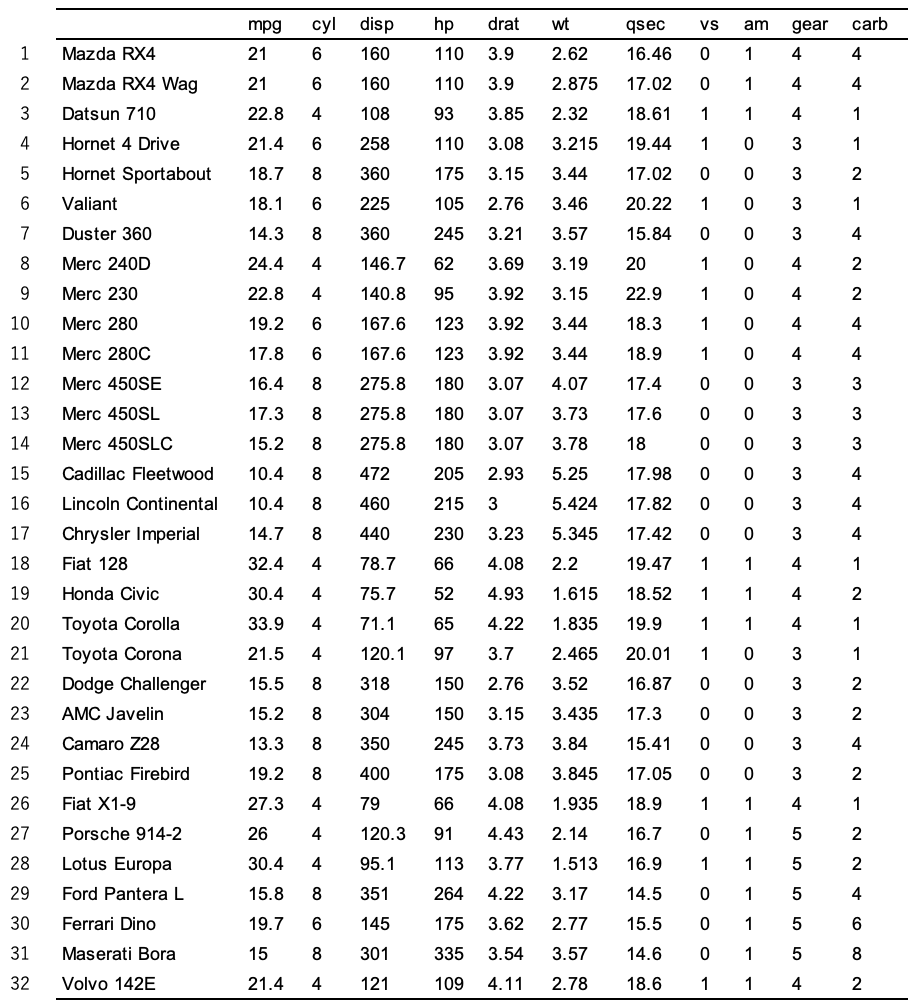
これを見てわかるように、特に右の4列のデータは1〜5の値を持っており、"disp"の列のデータは約70〜500の値を持っています。
したがって、これらの数値を、同じ土俵で比べてはいけないということになります。
この問題に対処するため、以下のように実行する必要があります。
> hv <- heatmap.2(data, scale = "column")ヒートマップは、以下のように得られます。
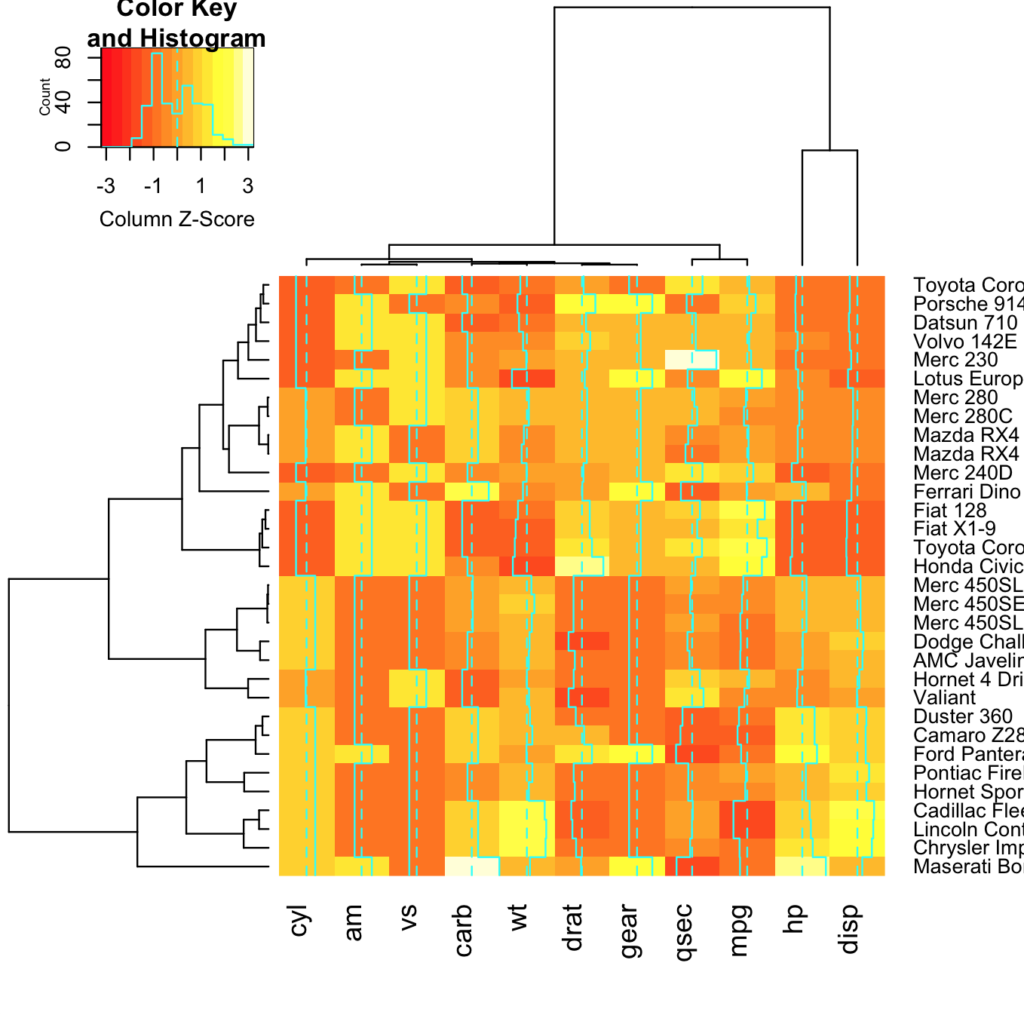
「scale = "column"」は、「すべての列について、平均が0、標準偏差が1になるように正規化してください」ということを意味しています。
つまり、図1では、ある指標は、1~5の値を持っていて、また別の指標は、約70〜500を持つというように、指標間でばらつきがあったので、どの指標をみても、(この場合には)-3〜3という値を持つように、データを変換した上で、ヒートマップを作成した結果が図2になります。
デフォルトの条件では、明記はしていないですが「scale = "none"」となっているので注意が必要です。
ヒートマップのラベルの情報だけを取得することも可能
今回示したヒートマップ(図1、図2)をみると、右に並んでいる車の名前(ラベル)が途中で切れてしまっています。
レイアウトに関するオプションである"lmat"などを活用して対処することも可能ですが、データが大きくなるほど、ラベルを区別することが難しくなります。
そこで、以下のように実行することで、行のラベルの名前、列のラベルの名前を手にいれることができます。
> row.names(data)[hv$rowInd] #行のラベルの名前
> colnames(data)[hv$colInd] #列のラベルの名前
とても便利なので、困った時には、ぜひ活用してみてください。
