
こんにちは、みっちゃんです。
前回の記事で、「決定木」が私たちの身近なところで活用されていることを紹介しました。
今回は、実際に手持ちのデータ(Excel)から、決定木を作成して、可視化するまでの手順を、Pythonを用いて紹介します。
目次(まとめ)
- エクセルで作ったデータ表をそのまま読み込む
- 読み込んだデータを正しく分類できる決定木を構築
- 出力ファイルをネット上のツールで可視化
エクセルで作ったデータ表をそのまま読み込む
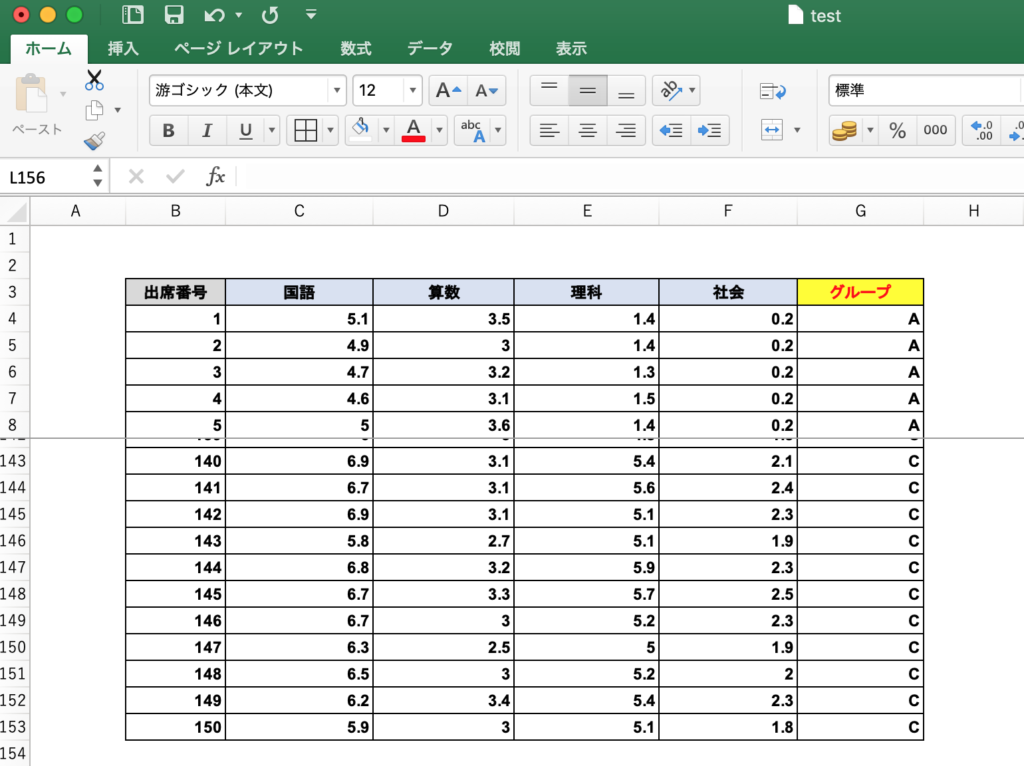
今回は、「150人の生徒を、それぞれの生徒の国語・算数・理科・社会の点数を元に、3つのグループに分ける決定木を作る」という問題を考えます。
点数にしては値が小さいですが、無視してください(irisのデータを転用しています)。
「すでにグループが分かっているのに、何のために決定木を作るの?」と疑問に思われるかもしれませんが、一旦決定木を作っておけば、151人目の生徒をどのグループに割り振るべきか一目瞭然になるからです。
まず、読み込むデータをエクセルを使って準備し、CSV形式(コンマ区切り)で保存します(図1; ここでは、test.csvとします)。
CSVファイルの読み込みのため、Pythonのpandasライブラリを使用します。pandasはデータ解析をする上で、必須ツールです。以下のように入力します。
$ python
>>> import pandas as pd"as pd"というのは、プログラム中で毎回"pandas"と書くのが面倒なので、略語としての"pd"を用いるという意味です。
※もしエラーとなれば、pandasがインストールされていない可能性があるので、インストールしてください(以前の記事で紹介しています)。
pandasには、"read_csv"という、CSVファイルを読み込むメソッドが準備されているので、以下のように実行します。
>>> data_frame = pd.read_csv('test.csv')これで、CSVファイルが、data_frameという変数(データフレーム型)に保存されました。
読み込んだデータを正しく分類できる決定木を構築
決定木は、機械学習のライブラリである”scikit-learn”の中で用意されています。
以下のように実行します。
>>> from sklearn import tree
>>> classifier = tree.DecisionTreeClassifier(max_depth = 2)※もしエラーとなれば、scikit-learnがインストールされていない可能性があるので、インストールしてください(以前の記事で紹介しています)。
scikit-learnライブラリから、treeメソッドを呼び出し、その中のクラスであるDecisionTreeClassifierを用いて分類器を定義しています。max_depthは、最大の木の深さを意味しています。
前準備はこれで終わりです。
ここから実際に、"data_frame"という変数に保存したデータを用いて、決定木を構築します。以下のように実行します。
>>> clf = clf.fit(data_frame.iloc[:,1:5], data_frame.iloc[:,5:6])"iloc"というのは、data_frameから、データの位置座標をもとに必要なデータを取り出すツールです。
「位置座標とは?」と思われると思いますが、pythonでは、1つの列を2つの数字で表現します。
例えば、読み込んだデータ全体の中から「出席番号」の列の情報だけ抜き出したい場合には、以下のように実行します。
>>> data_frame.iloc[:,0:1]iloc[行, 列]という指定をしていて、行の":"は全ての行を意味しています。同じように、「国語」の列の情報だけを抜き出したければ、以下のように実行します。
>>> data_frame.iloc[:,1:2]したがって、今、決定木を描くために実行した文は、「すべての生徒の国語・算数・理科・社会の点数」と「すべての生徒のグループ」の情報を指定しているということになります。
出力ファイルをネット上のツールで可視化
ここでは、Graphvizというグラフを書くためのソフトウェアを使って、決定木を可視化します。
Graphvizへの入力ファイルは、「DOT言語で記述したグラフ構造」なので、Python上で準備します。
treeメソッドの中でクラスが用意されているので、以下のように実行します。
>>> f = tree.export_graphviz(clf, out_file = 'test.dot', feature_names = ["Kokugo", "Sansu", "Rika", "Shakai"], class_names = ["A", "B", "C"], filled = True, rounded = True)"feature_names"には「テストの種類」、"class_names"には「グループの名前」を入力します。これを実行すると、"test.dot"というファイルが生成されます。
これをWeb版のGraphvizで可視化するのが一番簡単だと思います(図2)。
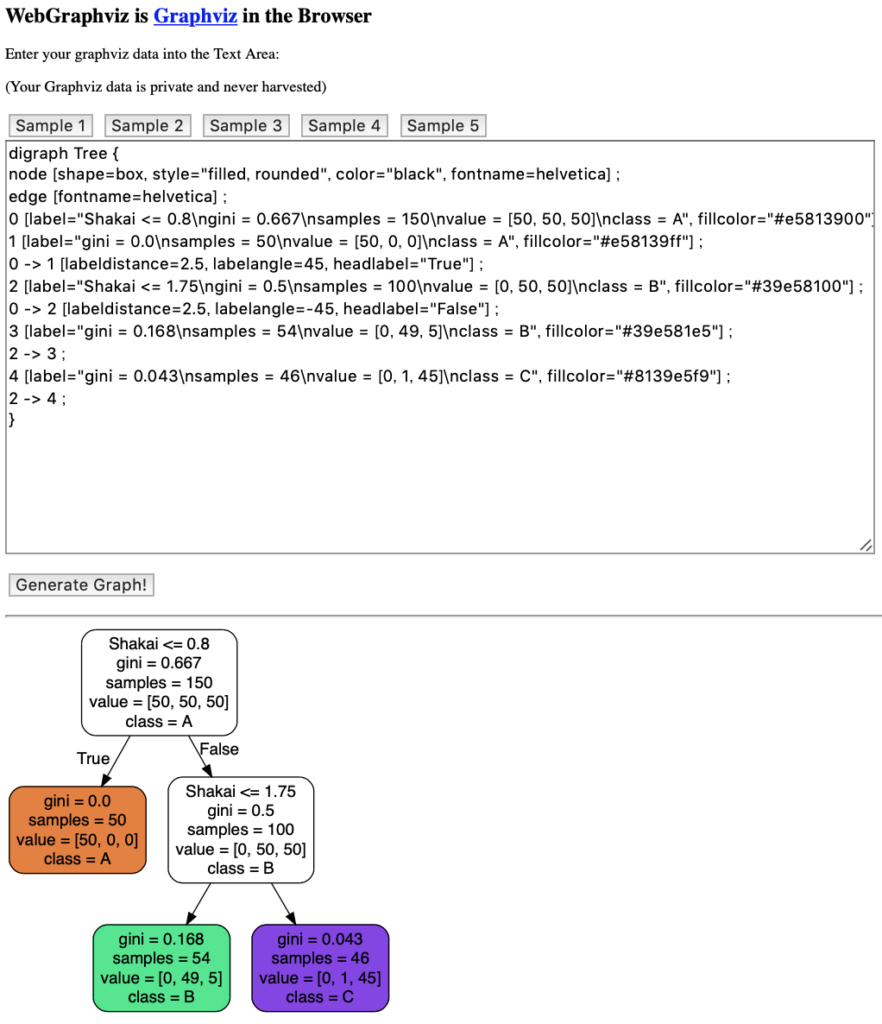
可視化した決定木の見方については、こちらの記事をご覧ください。
また、応用編ですが、構築された決定木がどれぐらい正しくグループ分けしているのか、以下のように実行して確認できます。
>>> predicted = clf.predict(data_frame.iloc[:,1:5])
>>> print(predicted)みなさんも、手持ちのデータを決定木として、可視化してみてください。
