
目次(まとめ)
◾️ 行名はrownames、列名はcolnamesを使って取得する
◾️ それぞれの要素は、インデックスや行/列名で指定する
◾️ 関連記事

こんにちは、みっちゃんです。
Rを使ってデータ処理をしたいけれど、読み込んだデータのそれぞれの要素をどのように指定したらいいのかわかりません。

要素を指定するための方法はいろいろありますが、基本的な方法を理解しておけば、応用がきくと思います。
今回の記事では、Rで必要な要素を指定して取り出す方法を紹介します。
行名はrownames、列名はcolnamesを使って取得する
ここでは、以下のようなエクセルデータを "test.csv" という名前でデスクトップに保存して、説明に用います。
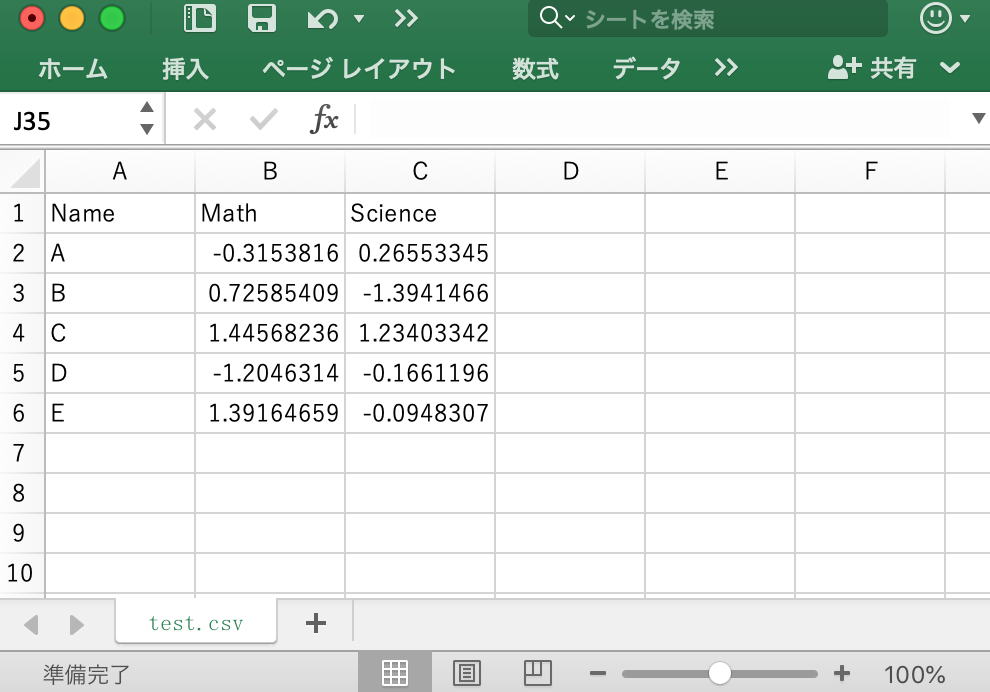
"test.csv" は、CSV(コンマ区切り)ファイルなので、Rで以下のように読み込むことができます。
$ R -q
> data <- read.csv("~/Desktop/test.csv", header = T, row.names = 1)
> data
Math Science
A -0.3153816 0.26553345
B 0.7258541 -1.39414658
C 1.4456824 1.23403342
D -1.2046314 -0.16611958
E 1.3916466 -0.09483074ここで、読み込むときに使用しているオプションには、以下のような意味があります。
| オプション | 値と意味 |
| header | "T" に指定すると、読み込むファイルの先頭行をヘッダー行として見なすことができます。もしヘッダー行がないファイルを読み込む場合には、"F" を指定します。 |
| row.names | "1" を指定すると、読み込むファイルの1列目を行の名前を示す列として見なすことができます。もし行の名前を示す列がないファイルを読み込む場合には、このオプションは不要です。 |
読み込んだデータは、"data" という変数に保存されていますが、この変数について、ヘッダー行(列名)を得るためには、以下のように実行します。
> colnames(data)
[1] "Math" "Science""col" とは、"列" の英語である "column" の略です。
同じように、"data" 変数について、先頭列(行名)を得るためには、以下のように実行します。
> rownames(data)
[1] "A" "B" "C" "D" "E""row" とは、"行" の英語です。
それぞれの要素は、インデックスや行/列名で指定する
ここで、もう一度、"data" 変数の中身を確認しておきます。
> data
Math Science
A -0.3153816 0.26553345
B 0.7258541 -1.39414658
C 1.4456824 1.23403342
D -1.2046314 -0.16611958
E 1.3916466 -0.09483074いま「CさんのScienceの値を教えてください」と言われれば、みなさん「1.23403342」と答えることができると思います。
Rでのプログラミングで、この答え「1.23403342」を得るためには、2つの方法が考えられます。
1つ目は「(行/列名は除いて)3行目2列目の値を得る」という方法です。
この方法では、以下のように実行します。
> data[3, 2]
[1] 1.23403342行番号と列番号を指定するだけなので、簡単ですね。
ただし、この方法は、"data" 変数の全体像が見えているとき、つまり、小さい行列データであれば使うことができますが、大きな行列になると使いづらくなります。
そんなときは、2つ目の方法が便利です。
2つ目は、より直接的に「Cさん行のScience列の値を得る」という方法です。
この方法では、以下のように実行します。
> data[rownames(data)=="C", colnames(data)=="Science"]
[1] 1.23403342つまり、「"data" 変数の行名が "C" になっている行で、"data" 変数の列名が "Science" になっている列にある値」を指定しているわけです。
注意点は、「一致しているか」の判定記号として、イコールを2つ書くという点です。ご注意ください。
また、以下のように実行すれば、「CさんのMathとScienceの値を得る」ことができます。
> data[rownames(data)=="C", ]
Math Science
C 1.4456824 1.23403342