
目次(まとめ)
- 9. データから、指定する文字列を含む行だけを抽出する
- 10. 2項目のデータを用いて散布図を作成する
- 11. 2項目のデータの相関係数を算出する
こんにちは、みっちゃんです。
前回の記事では「プログラミングをやってみたいけれど、手元のデータからどうやって始めたらいいかわからない」という方向けに、実際のデータをダウンロードするところから、Rを使ったデータ解析手順(読み込み/グラフ作成)を紹介しました。
今回の記事では、前回のつづきとして、Rを使ったデータ解析手順(相関解析)を紹介したいと思います。
9. データから、指定する文字列を含む行だけを抽出する
前回の記事で紹介したように、国勢調査のデータをRで読み込みます。
> data <- read.csv("/Users/***/Downloads/001_00.csv", fileEncoding = "CP932", skip = 9, header = T)以下のように、項目名およびデータの一部を表示します。
> names(data)
[1] "X10" "X.大項目"
[3] "地域コード" "地域識別コード"
[5] "境域年次.2015." "境域年次.2000."
[7] "X" "人口.平成27年..a."
[9] "人口.平成22年.組替..2.." "平成22年.27年の人口増減数.2.."
[11] "平成22年.27年の人口増減率....2.." "面積.km2...b..1..2.."
[13] "人口密度.1km2当たり...a...b..2." "世帯数.平成27年."
[15] "世帯数.平成22年.組替..2.." "平成22年.27年の世帯数増減数.2.."
[17] "平成22年.27年の世帯数増減率....2."> head(data)
X10 X.大項目 地域コード 地域識別コード 境域年次.2015. 境域年次.2000. X
1 11 NA 0 a 2015 2000 全国
2 12 NA 1 b 2015 2000 市部
3 13 NA 2 b 2015 2000 郡部
4 14 NA 1000 a 2015 2000 北海道
5 15 NA 1001 b 2015 2000 市部
6 16 NA 1002 b 2015 2000 郡部
人口.平成27年..a. 人口.平成22年.組替..2.. 平成22年.27年の人口増減数.2..
1 127094745 128057352 -962607
2 116137232 116549098 -411866
3 10957513 11508254 -550741
4 5381733 5506419 -124686
5 4395172 4449360 -54188
6 986561 1057059 -70498
平成22年.27年の人口増減率....2.. 面積.km2...b..1..2..
1 -0.7516999102 377970.75
2 -0.3533841163 216973.76
3 -4.7856173491 160912.77
4 -2.2643754498 83424.31
5 -1.2178830214 18536.20
6 -6.6692587642 64829.10
人口密度.1km2当たり...a...b..2. 世帯数.平成27年. 世帯数.平成22年.組替..2..
1 340.8 53448685 51950504
2 535.5 49319924 47812998
3 70.2 4128761 4137506
4 68.6 2444810 2424317
5 238.3 2021698 1989236
6 16.5 423112 435081
平成22年.27年の世帯数増減数.2.. 平成22年.27年の世帯数増減率....2.
1 1498181 2.8838623009
2 1506926 3.1517078264
3 -8745 -0.2113592101
4 20493 0.8453102461
5 32462 1.6318827932
6 -11969 -2.7509820011
これらのデータを確認すると、7列目の "X" には「都市名」が記載されていることがわかります(ダウンロードしたExcelファイルでも確認できます)。
例えば、データの1行目は「全国」のデータになっており、その行だけを取り出すためには、以下のように実行します。
> data[data$X=="全国", ]「data[行番号、列番号]」という形式でデータを取れるのですが、いま行番号として「data$Xの情報が "全国" になっている行の番号」を設定しています。
実行すると、以下のような結果が得られます。
> data[data$X=="全国", ]
X10 X.大項目 地域コード 地域識別コード 境域年次.2015. 境域年次.2000. X
1 11 NA 0 a 2015 2000 全国
人口.平成27年..a. 人口.平成22年.組替..2.. 平成22年.27年の人口増減数.2..
1 127094745 128057352 -962607
平成22年.27年の人口増減率....2.. 面積.km2...b..1..2..
1 -0.7516999102 377970.8
人口密度.1km2当たり...a...b..2. 世帯数.平成27年. 世帯数.平成22年.組替..2..
1 340.8 53448685 51950504
平成22年.27年の世帯数増減数.2.. 平成22年.27年の世帯数増減率....2.
1 1498181 2.8838623009
このような書き方の場合、「data$X」が「全国」という単語に一致していなければなりません。
それでは、例えば、「札幌市」に関わるデータを取り出したい場合にはどうしたらいいでしょうか?
この場合には、以下のように実行します。
> data[grep("札幌市", data$X), ]先ほどと同様に「data[行番号、列番号]」という形式でデータを取っているのですが、いま行番号として「data$Xの情報に "札幌市" という単語を含んでいる行の番号」を設定しています。
「grep(A, B)」とすると、Bの中からAの情報を含むデータを検索します。
実行結果は、以下のようになります(一部抜粋しています)。
> data[grep("札幌市", data$X), ]
:
X 人口.平成27年..a. 人口.平成22年.組替..2..
7 札幌市 1952356 1913545
8 札幌市 中央区 237627 220189
9 札幌市 北区 285321 278781
10 札幌市 東区 261912 255873
11 札幌市 白石区 209584 204259
12 札幌市 豊平区 218652 212118
13 札幌市 南区 141190 146341
14 札幌市 西区 213578 211229
15 札幌市 厚別区 127767 128492
16 札幌市 手稲区 140999 139644
17 札幌市 清田区 115726 116619
4508 札幌市 人口集中地区 1899081 1846399
4509 札幌市 中央区 人口集中地区 235356 217633
4510 札幌市 北区 人口集中地区 275495 261235
4514 札幌市 東区 人口集中地区 255507 249599
4517 札幌市 白石区 人口集中地区 205645 200377
4518 札幌市 豊平区 人口集中地区 217832 210803
4519 札幌市 南区 人口集中地区 122354 127198
4520 札幌市 西区 人口集中地区 211996 209283
4521 札幌市 厚別区 人口集中地区 125771 126264
4522 札幌市 手稲区 人口集中地区 137016 134390
4523 札幌市 清田区 人口集中地区 112109 109617
:このように、「札幌市」関連のデータのみを取り出すことができます。
10. 2項目のデータを用いて散布図を作成する
ここでは、札幌市関連の地域について、「人口」と「人口密度」の関係をグラフとして表示することを考えます。
まず「人口」の情報は、以下のように取得することができます。
> data$人口.平成27年..a.[grep("札幌市", data$X)]
[1] 1952356 237627 285321 261912 209584 218652 141190 213578 127767
[10] 140999 115726 1899081 235356 275495 255507 205645 217832 122354
[19] 211996 125771 137016 112109
また「人口密度」の情報は、以下のように取得することができます。
> data$人口密度.1km2当たり...a...b..2.[grep("札幌市", data$X)]
[1] 1741.2 5119.1 4488.3 4597.4 6080.2 4729.7 214.7 2843.9 5240.6
[10] 2483.7 1933.0 8064.0 10246.2 7743.0 7982.1 8710.1 10029.1 6261.7
[19] 8462.9 7544.8 6340.4 6689.1
「人口」と「人口密度」の関係をグラフで表現するため、散布図を使用します。
描き方は以下の通りです。
> plot(data$人口.平成27年..a.[grep("札幌市", data$X)], data$人口密度.1km2当たり...a...b..2.[grep("札幌市", data$X)], xlab = "Population", ylab = "Population density")実行すると、以下のような図が作成されます。
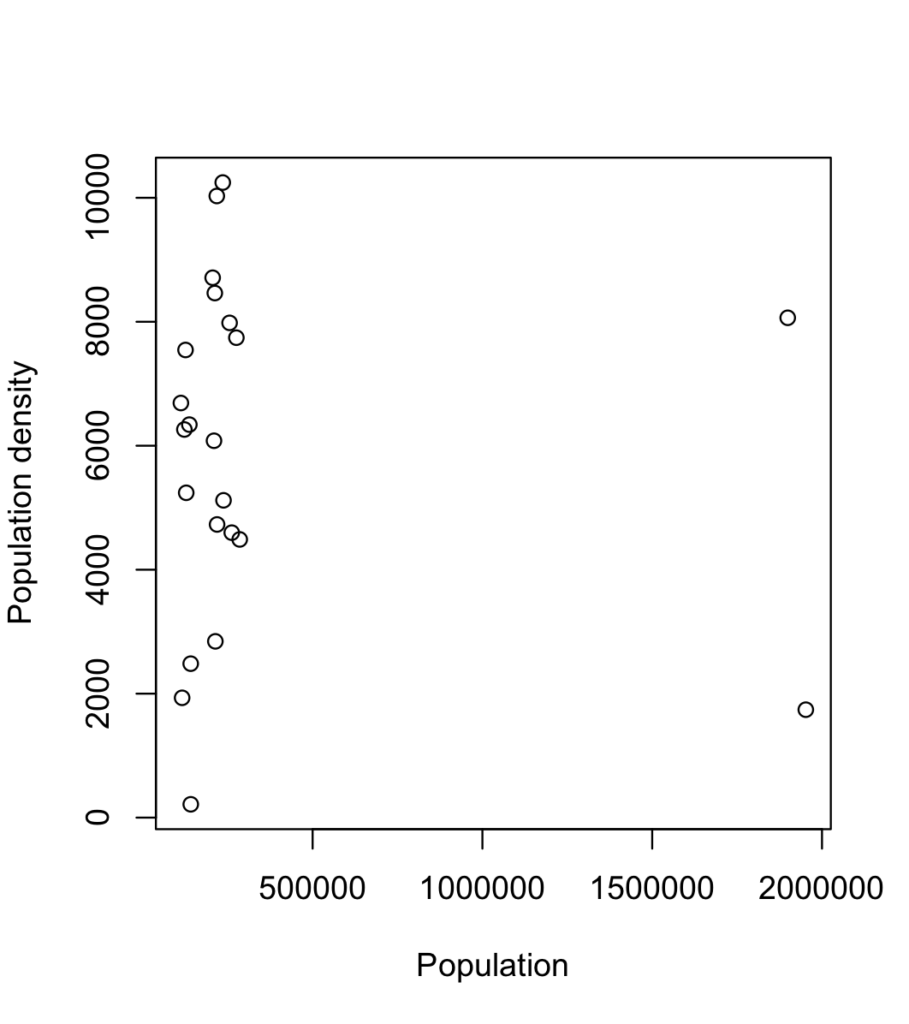
11. 2項目のデータの相関係数を算出する
上で描いた散布図を見ると、「人口」と「人口密度」との間に相関があるのか明らかではありません。
数値として、相関の有無を評価するため「相関係数」という指標があります。
以下のように計算することができます。
> cor(data$人口.平成27年..a.[grep("札幌市", data$X)], data$人口密度.1km2当たり...a...b..2.[grep("札幌市", data$X)])実行すると「-0.07984487」という数値が出てきます。
この数値は、ほとんど相関はないものの、人口が多い地域ほど人口密度が低い傾向があることを示しています。
散布図を見ると、全体とは違う数値を示すような点(外れ値)がありそうなので、その影響が考えられます。
相関解析を行う際には、数値としての相関係数と、実際の散布図を見比べることも重要です。
