目次(まとめ)
- 6. 読み込んだデータの概要を把握する
- 7. 実際にデータの一部を表示する
- 8. データの一部を指定してグラフを作成する
こんにちは、みっちゃんです。
前回の記事では「プログラミングをやってみたいけれど、手元のデータからどうやって始めたらいいかわからない」という方向けに、実際のデータをダウンロードするところから、Rを使ったデータ解析手順(読み込み)を紹介しました。
今回の記事では、前回のつづきとして、Rを使ったデータ解析手順(グラフ作成)を紹介したいと思います。
6. 読み込んだデータの概要を把握する
前回の記事で紹介したように、国勢調査のデータをRで読み込みます。
> data <- read.csv("/Users/***/Downloads/001_00.csv", fileEncoding = "CP932", skip = 9, header = T)「skip = 9」としてデータを読み込んだため、総務省のWebサイトからダウンロードしたファイルの上9行が削除され、「header = T」としたため、10行目がヘッダーとして「data」に読み込まれています。
それでは、実際に読み込んだファイルは、どのようなもの何でしょうか?
例えば、何行のデータがあって、項目(列)の数はどれぐらいあるのでしょうか?
「data」の大きさ(行の数と列の数)を取得するためには、以下のように実行します。
> dim(data)「dim(・)」とは、dimension(次元)の略であり、「dim(data)」とすると「data」の次数(行の数と列の数)を取得することができます。
実行結果は、以下のようになります。
> dim(data)
[1] 6353 17ここでは、先頭の "[1]" は無視して大丈夫です。
"6553" が「data」の行数、"17" が「data」の列数に対応します。
つまり、この「data」は、全部で6553行あり、それぞれの行に対して17個の項目があるデータであるということがわかります。
7. 実際にデータの一部を表示する
それでは、その「項目」とは具体的に何なのでしょうか?
実は、この「項目」とは、ヘッダー行として読み込んだ行に記載されているものです。
R上でその内容を確認するためには、以下のように実行します。
> names(data)実行結果は以下のようになります。
> names(data)
[1] "X10" "X.大項目"
[3] "地域コード" "地域識別コード"
[5] "境域年次.2015." "境域年次.2000."
[7] "X" "人口.平成27年..a."
[9] "人口.平成22年.組替..2.." "平成22年.27年の人口増減数.2.."
[11] "平成22年.27年の人口増減率....2.." "面積.km2...b..1..2.."
[13] "人口密度.1km2当たり...a...b..2." "世帯数.平成27年."
[15] "世帯数.平成22年.組替..2.." "平成22年.27年の世帯数増減数.2.."
[17] "平成22年.27年の世帯数増減率....2."一部、R上で表せていない文字が存在するので、詳細はExcelで確認する必要がありますが、地域や人口、面積、人口密度などの情報が記載されているデータであることがわかります。
なお、先頭の "[1]"などは項目(列)の番号で、"X10" が1列目、"X.大項目" が2列目に相当します。
次に、項目名だけではなく、データの中身が知りたいと思うかもしれません。
ここで注意してほしいことは、いま読み込んでいるデータが6553行×17列という、かなり大きいデータであるということです。
(おすすめはしないですが)データの全体を表示するためには、以下のように実行します。
> data大きいデータを全て表示せず、データの一部を表示する、つまり、データの上から数行だけを例として表示するためには、以下のように実行します。
> head(data)実行結果は以下のようになります。
> head(data)
X10 X.大項目 地域コード 地域識別コード 境域年次.2015. 境域年次.2000. X
1 11 NA 0 a 2015 2000 全国
2 12 NA 1 b 2015 2000 市部
3 13 NA 2 b 2015 2000 郡部
4 14 NA 1000 a 2015 2000 北海道
5 15 NA 1001 b 2015 2000 市部
6 16 NA 1002 b 2015 2000 郡部
人口.平成27年..a. 人口.平成22年.組替..2.. 平成22年.27年の人口増減数.2..
1 127094745 128057352 -962607
2 116137232 116549098 -411866
3 10957513 11508254 -550741
4 5381733 5506419 -124686
5 4395172 4449360 -54188
6 986561 1057059 -70498
平成22年.27年の人口増減率....2.. 面積.km2...b..1..2..
1 -0.7516999102 377970.75
2 -0.3533841163 216973.76
3 -4.7856173491 160912.77
4 -2.2643754498 83424.31
5 -1.2178830214 18536.20
6 -6.6692587642 64829.10
人口密度.1km2当たり...a...b..2. 世帯数.平成27年. 世帯数.平成22年.組替..2..
1 340.8 53448685 51950504
2 535.5 49319924 47812998
3 70.2 4128761 4137506
4 68.6 2444810 2424317
5 238.3 2021698 1989236
6 16.5 423112 435081
平成22年.27年の世帯数増減数.2.. 平成22年.27年の世帯数増減率....2.
1 1498181 2.8838623009
2 1506926 3.1517078264
3 -8745 -0.2113592101
4 20493 0.8453102461
5 32462 1.6318827932
6 -11969 -2.7509820011
※ここでは、表示がガタついていますが、R上ではよりきれいに表示されますのでご安心ください。
8. データの一部を指定してグラフを作成する
例えば、いま取り扱っているデータの13列目は「人口密度」になっています(上で述べたように、names(data)から確認できます)。
この「人口密度」のデータだけを取り出したい場合には、「13列目」という情報から、以下のように実行できます(おすすめしません)。
> data[,13]「data[行番号、列番号]」の番号を指定することで、対象のデータを取り出すことができます。
この場合には、「13列目のデータ」を取り出しているのですが、行番号を空白にしていることで「6553行全てのデータ」を取り出してしまいます。
そこで、先ほどと同じように、以下のように実行すればOKです。
> head(data[,13])また「項目名」の情報を以下のように指定して、同じデータを取り出すこともできます。
> head(data$人口密度.1km2当たり...a...b..2.)※ "data$"と記入して「tab」キーを複数回押すと、候補がでてくるので参照できます。
ここでは、例として、ヒストグラムを作ることで、人口密度の分布を出してみます。
ヒストグラムは以下のように作成します。
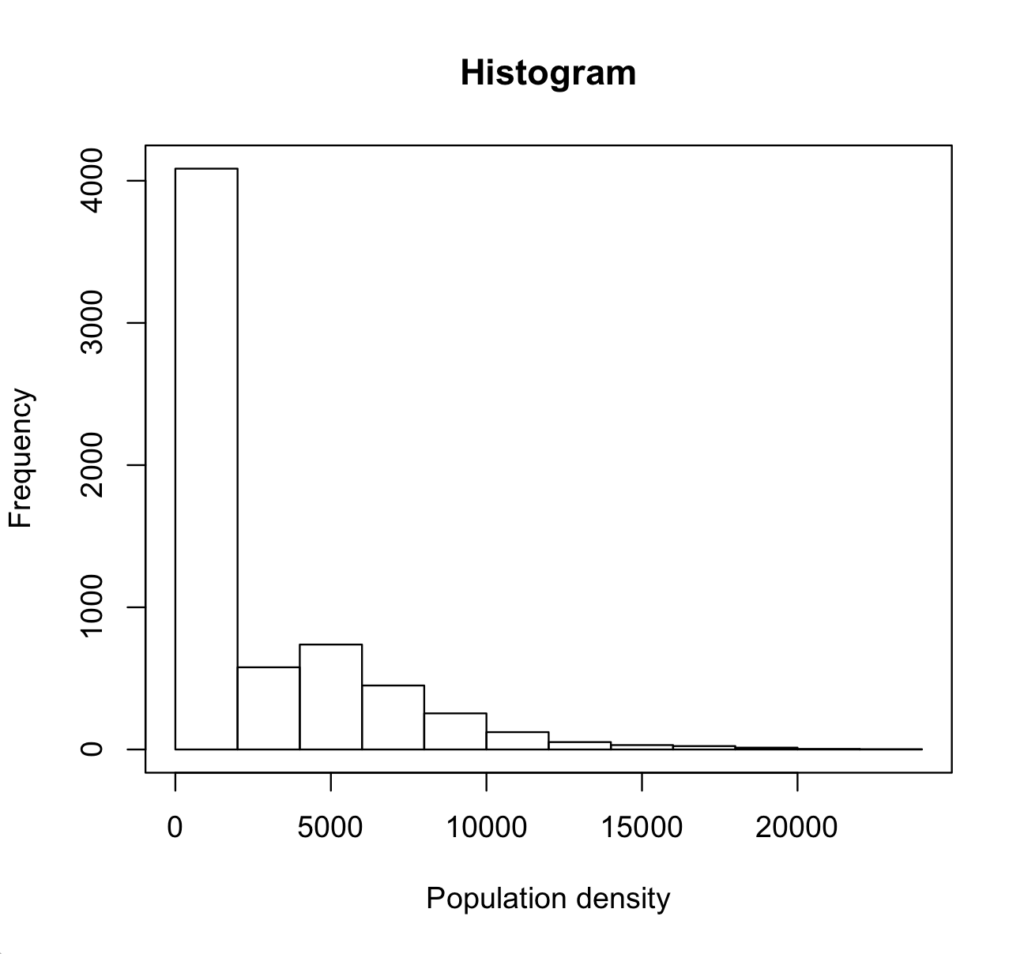
> hist(data$人口密度.1km2当たり...a...b..2.)
> box() #枠線でプロット全体を囲みたい場合実行すると、以下のような図が作成されます。
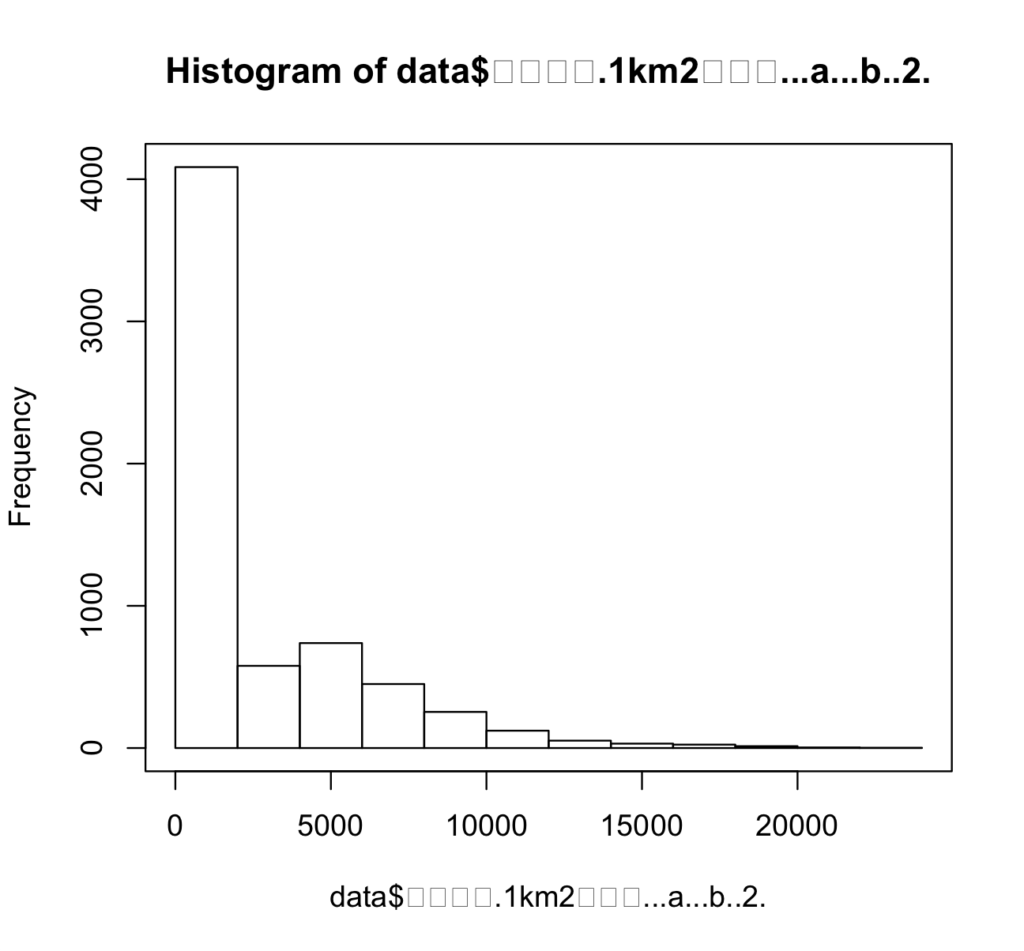
日本語は、文字化けされてしまうので、以下のように英語を別途指定して、図を修正することができます。
> hist(data$人口密度.1km2当たり...a...b..2., main = "Histogram", xlab = "Population density")
> box() #枠線でプロット全体を囲みたい場合